The problem
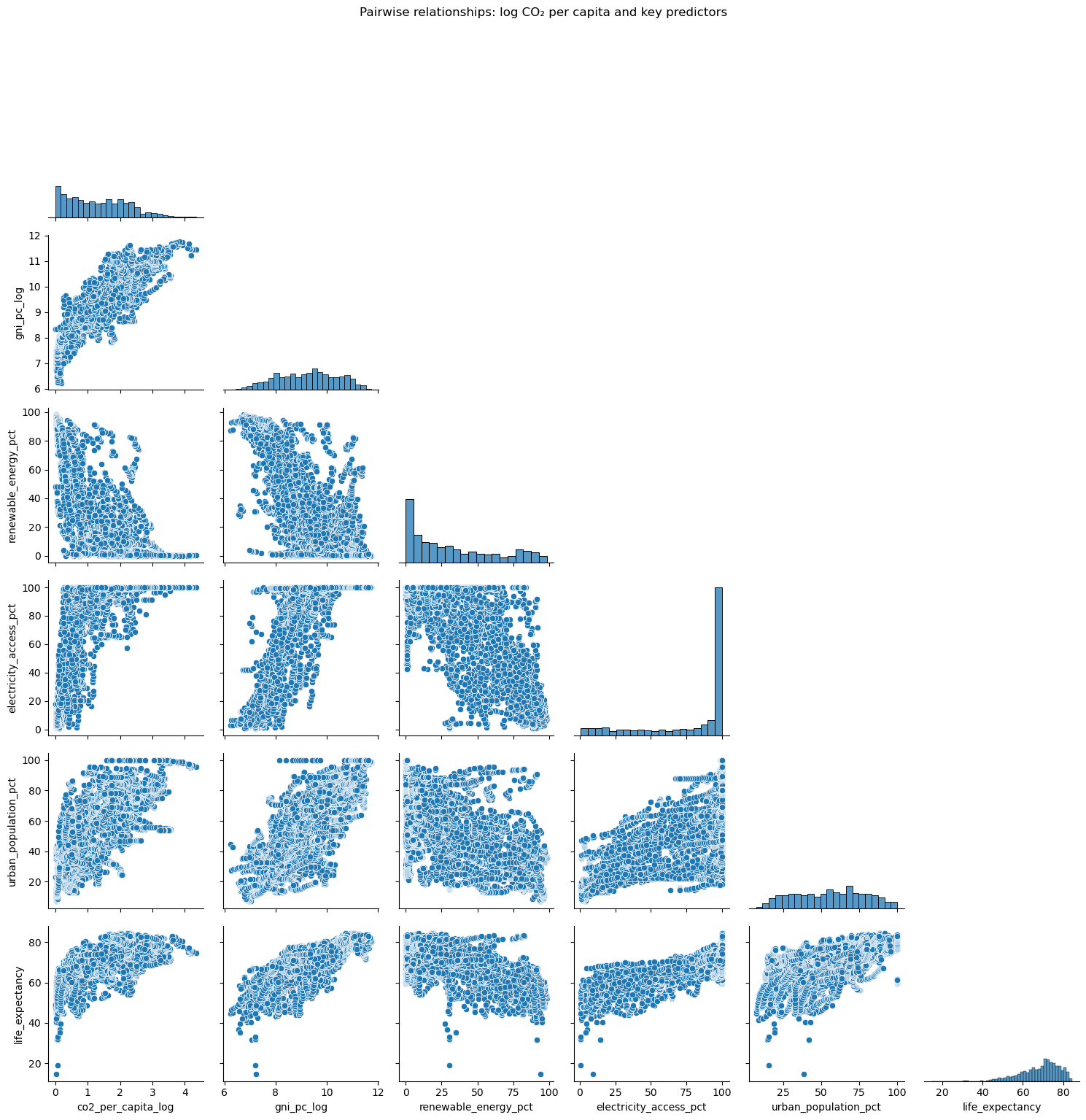
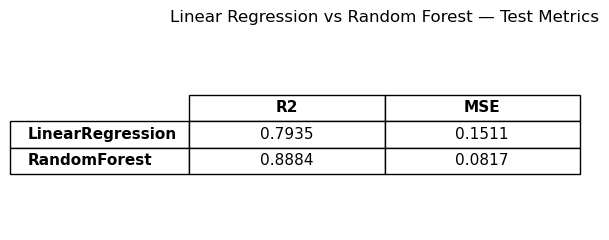
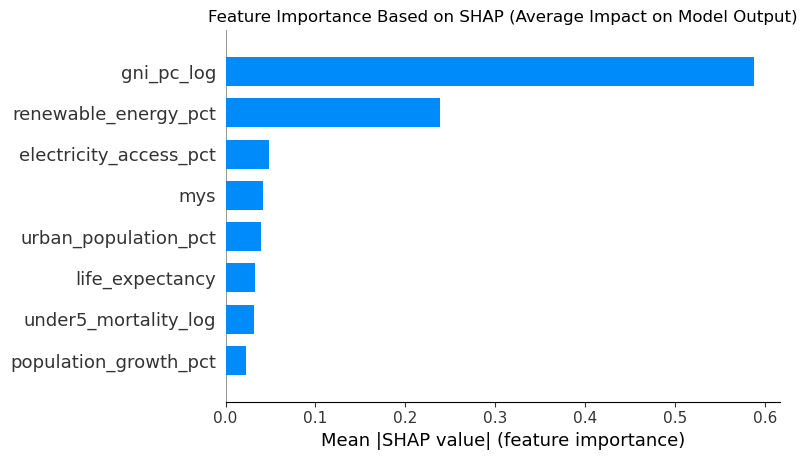
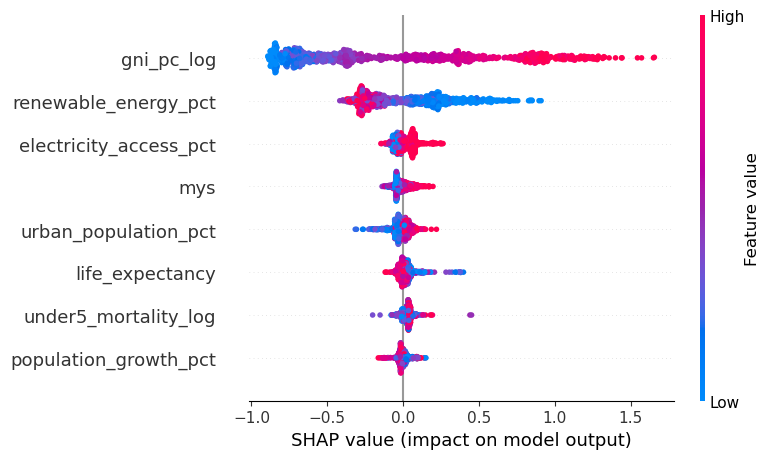
Governments, multilaterals and investors are expected to raise human development while simultaneously reducing emissions. In practice, those agendas are often monitored on separate dashboards rather than as a single system.
Without a structured view of how income, health, education, electricity access, renewables and urbanisation interact, climate policy frequently collapses into slogans and partial evidence.
The result is a real risk of expensive decarbonisation plans that ignore social realities, or development strategies that quietly lock in high-carbon pathways for decades.